- Uitleggen wat meetniveaus zijn.
Datapunten en datareeksen worden onderverdeeld in verschillende variabelen. Een variabele is bijvoorbeeld leeftijd of experimentele conditie. Variabelen kunnen verschillende meetniveaus hebben. - Opnoemen welke meetniveaus worden onderscheiden
Er worden vier soorten meetniveaus onderscheiden, te weten: nominaal, ordinaal, interval en ratio.
Nominaal: Het meest basale meetniveau in de statistiek, waarbij data in kwalitatieve categorieën wordt ingedeeld zonder een zinvolle rangorde of numerieke waarde. Categorieën sluiten elkaar wederzijds uit (bijv. geslacht, haarkleur, woonplaats).
Ordinaal: Het is een meetniveau in de statistiek waarbij gegevens kunnen worden gecategoriseerd én gerangschikt in een logische volgorde. Het verschil tussen de waarden is niet constant of meetbaar, wat betekent dat je wel kunt zeggen dat iets “meer” of “beter” is, maar niet precies hoeveel.
Interval: Het is een meetniveau waarbij data worden geordend en de afstanden (intervallen) tussen de waarden gelijk en betekenisvol zijn. Het heeft geen absoluut nulpunt.
Ratio: Het is het hoogste meetniveau in de statistiek, gekenmerkt door gelijke intervallen en een absoluut, betekenisvol nulpunt. Dit maakt het mogelijk om zinvolle verhoudingen te berekenen (bijv. 20 kg is dubbel zo zwaar als 10 kg). - Uitleggen waarom hogere meetniveaus de voorkeur verdienen boven lagere meetniveaus.
– Er zijn altijd meer deelnemers nodig naarmate het meetniveau van de betreffende variabelen lager is.
– Veel variabelen die we willen meten in onderzoek zijn continu.
– Het is altijd mogelijk om van een continue variabele terug te gaan naar lagere niveaus, maar niet andersom.
– Groepen mensen bestaan vaak niet uit duidelijk onderscheidbare subgroepen. Elke indeling in categorieën geeft dus vaak een vertekening van de werkelijkheid. Het meten van variabelen op een categorisch meetniveau vereist namelijk dat harde grenswaarden, zogenaamde ‘cut-offs’, worden gekozen. - Uitleggen wat beschrijvingsmaten zijn
Wanneer de dataverzameling van een onderzoek heeft plaatsgevonden en we beschikken over een databestand met alle gegevens, willen we vervolgens die gegevens op een zo overzichtelijke manier weergeven. Er zijn verschillende manieren om data samen te vatten in zogenaamde beschrijvingsmaten. Beschrijvingsmaten worden onderverdeeld in centrummaten en spreidingsmaten. - Uitleggen waar centrummaten voor gebruikt worden
Centrummaten geven op verschillende manieren het ‘centrum’ van een bepaalde datareeks aan. De meest gebruikte centrummaat in het dagelijkse leven is het gemiddelde. Andere belangrijke centrummaten zijn de mediaan en de modus. - Drie veelgebruikte centrummaten opnoemen en uitleggen wanneer elk gebruikt wordt.
Gemiddelde = De som van alle waarden, gedeeld door het totaal aantal waarden.
Wanneer gebruiken:
– Bij symmetrische, numerieke data zonder extreme uitschieters (bijv. lengte van mensen, testscores).
– Wanneer je elk datapunt wilt meenemen in de berekening.
Modus = de meest voorkomende waarde in de datareeks.
Wanneer gebruiken:
– Wanneer uitschieters er zijn.
– Bij nominale data (categorieën zonder volgorde, zoals haarkleur, favoriete sport of stemgedrag).
– Wanneer je wilt weten wat de meest populaire of typische categorie is.
Mediaan = het middelste datapunt in de datareeks.
Wanneer gebruiken:
– Bij scheve verdelingen of wanneer er extreme uitschieters zijn (bijv. inkomens, huizenprijzen). De mediaan is “robuuster”, wat betekent dat hij niet wordt beïnvloed door extreem hoge of lage waarden.
– Bij ordinale data (data die gerangschikt kan worden). - Uitleggen hoe deze centrummaten berekend worden.
Gemiddelde: de som van alle waarde, gedeeld door het totaal aantal waarden.
Modus: Dataset ordenen en meest voorkomende waarde zoeken
Mediaan: Dataset ordenen en middelste getal benoemen of berekenen als datareeks even aantal getallen bevat. - Uitleggen wat uitschieters zijn en welk effect ze hebben.
Een outlier, ook wel uitschieter of uitbijter genoemd, is een extreem datapunt. In de meeste gevallen ligt de outlier dan ook ver af van de rest van de datapunten. Outliers kunnen om verschillende redenen voorkomen, waaronder meetfouten, experimentele fouten, natuurlijke variabiliteit of werkelijke uitzonderlijke omstandigheden. Het is belangrijk om outliers te identificeren en te overwegen om hoe ermee om te gaan bij analyseren van gegevens, omdat ze de resultaten kunnen vertekenen. - Uitleggen waar spreidingsmaten voor gebruikt worden.
Spreidingsmaten worden gebruikt om de mate van verspreiding of spreiding van gegevens punten in een dataset te beschrijven. Het helpt onderzoekers en analisten beter te begrijpen hoe uitgespreid of geconcentreerd de gegevens zijn. - Vier veelgebruikte spreidingsmaten opnoemen en uitleggen wanneer elk gebruikt wordt.
– De eenvoudigste spreidingsmaat is de range, ook wel het bereik, van een variabele. Dit is simpelweg het verschil tussen het maximum en het minimum. Het is zeer gevoelig voor outliers.
Wanneer gebruiken? Voor een snelle en eenvoudige eerste indruk van de spreiding in een dataset.
– De interkwartielafstand (in het Engels de interquartile range, oftewel IQR) is voor spreidingsmaten wat de mediaan is voor centrummaten.
Wanneer gebruiken? Als de dataset scheef is verdeeld of sterke uitschieters bevat. Het is een “robuuste” maat, wat betekent dat uitschieters de uitkomst nauwelijks beïnvloeden.
– Variatie of sum of squares is de som van de gekwadrateerde afwijkingen van het gemiddelde.
– Variantie: Het gemiddelde van de kwadratische afwijkingen van het gemiddelde. Houdt rekening met het aantal datapunten en is daarom informatiever dan de sum of squares.
Wanneer gebruiken? Vaak gebruikt in theoretische statistiek en bij het berekenen van variantie-analyses (ANOVA), omdat het wiskundig makkelijker te bewerken is dan de standaardafwijking.
– Standaarddeviatie: Een maat voor de gemiddelde afwijking van alle meetwaarden ten opzichte van het gemiddelde.
Wanneer gebruiken? Bij symmetrische verdelingen (zoals de normaalverdeling) om te begrijpen hoe dicht de data bij het gemiddelde liggen. - Uitleggen hoe deze spreidingsmaten berekend worden
Range= max – min
IQR=Q3-Q1
Variatie =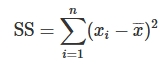
Variantie = variatie/n-1
Standaarddeviatie is wortel van variantie. - Beschrijven wat vrijheidsgraden zijn.
Vrijheidsgraden, oftewel degrees of freedom (df) in het Engels, drukken uit hoeveel datapunten in een datareeks vrij kunnen variëren zonder dat de berekende statistiek verandert. - Uitleggen hoe categorische variabelen beschreven kunnen worden.
Categorische variabelen kunnen met sommige centrummaten (modus, mediaan) beschreven worden maar ze geven weinig informatie over verdeling van een categorische variabelen. Met frequentieverdeling kan eenvoudig bepaald worden hoe vaak elke meetwaarde voorkomt. - Beschrijven wat frequentieverdelingen zijn.
Een frequentieverdeling is een overzicht dat laat zien hoe vaak elke categorie in de dataset voorkomt. Het kan worden weergegeven in een staafdiagram, waarbij de hoogte van elke staaf de frequentie van de bijbehorende categorie aangeeft. - Uitleggen wat verdelingsvormen zijn.
Datareeksen worden meestal verzameld om informatie te krijgen over een populatie. Dit maakt dat de patronen in datareeksen belangrijker dan individuele datapunten. Datareeksen hebben altijd een verdeling. In de statistiek zijn allerlei verdelingsvormen bekend die gebruikt kunnen worden om data efficiënt te beschrijven. Over het algemeen zijn er drie termen die gebruikt worden om een verdelingsvorm te beschrijven, de modaliteit (‘toppigheid’), de scheefheid (‘skewness’) en de spitsheid (‘kurtosis’) van een verdeling. - Opnoemen welke verdelingsmaten er zijn.
De mate van aanwezigheid van verdelingvormen (modaliteit, scheefheid, spitsheid) kunnen getoetst worden met de volgende verdelingsmaten: de Hartigans’ dip test (unimodaliteit), skewness (scheefheid) en kurtosis (spitsheid). - Uitleggen wat elke verdelingsmaat voorstelt.
– Hartigans dip test: Een perfect unimodale verdeling heeft een diptest waarde van . Naarmate een verdeling ‘meertoppiger’ lijkt te zijn – dus minder duidelijk eentoppig – wordt deze waarde steeds groter.
– Skewness: Bij een perfect symmetrische verdeling ligt deze maat in de buurt van . Naarmate een verdeling meer linksscheef is, wordt de skewness steeds kleiner (dat is, meer negatief) en naarmate een verdeling meer rechtsscheef is, wordt de skewness steeds groter (dat is, meer positief).
– Kurtosis: De kurtosis is bij een perfect normale verdeling. Naarmate een verdeling platter is, wordt de kurtosis steeds kleiner (dat is, meer negatief) en naarmate een verdeling spitser is, wordt de kurtosis steeds groter (dat is, meer positief) - Beschrijven wat de normale verdeling is.
Normale verdeling is een verdeling die niet op de een of andere manier afwijkend is.Deze verdeling heeft een aantal kenmerken:
– De normaalverdeling is unimodaal.
– De normaalverdeling is niet scheef (en dus perfect symmetrisch).
– De normaalverdeling is niet bijzonder spits of plat.
van de datapunten (ongeveer twee derde) ligt binnen ongeveer één standaarddeviatie van het gemiddelde.
van de datapunten ligt binnen ongeveer twee standaarddeviaties van het gemiddelde.
van de datapunten (dus bijna allemaal) ligt binnen ongeveer drie standaarddeviaties van het gemiddelde. - Beschrijven wat z-scores zijn.
Een speciale vorm van de normale verdeling is een normaalverdeling met een gemiddelde van en een standaarddeviatie van . Dit heet een standaardnormale verdeling of z-verdeling. Datapunten in een z-verdeling heten z-scores. Datapunten om rekenen in z-scores heet standaardisering.
Formule: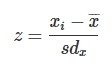
- Beschrijven wat histogrammen zijn.
De histogrammen zijn opgestapelde blokjes, waarbij elk blokje voor één deelnemer (datapunt) stond, en waarbij die blokjes op de x-as werden geplaatst bij de corresponderende meetwaarde van de desbetreffende variabele. - Beschrijven wat density plots zijn.
De normaalverdeling wordt meestal niet weergegeven in een histogram, maar met een mooie soepele lijn. Deze lijn geeft de zogenaamde ‘dichtheid’ (‘density’ in het Engels) van de verdeling aan, oftewel hoeveel datapunten er voor een gegeven meetwaarde zijn, en wordt daarom ook wel een density plot genoemd. Deze plot drukt uit welke proportie van de datapunten ergens zit ten opzichte van het totale aantal datapunten. - Beschrijven wat Q-Q-plots zijn.
De Q-Q-plot splitst de data in zogenoemde kwantielen (‘quantiles’, daarom ‘Q’). Kwantielen zijn de breekpunten tussen even grote delen van de data. Eerder ben je kwantielen, in de vorm van kwartielen, al tegengekomen bij het bespreken van de mediaan en de interkwartielafstand. Andere veelgebruikte kwantielen zijn bijvoorbeeld ‘percentielen’ ( breekpunten die de datareeks in honderd delen splitsen). Als een datareeks niet normaal is verdeeld, wijken de stipjes van de diagonale lijn af.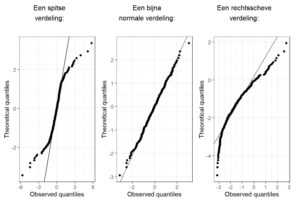
- Beschrijven wat boxplots zijn.
In een boxplot worden drie kwartielen geplot, dat wil zeggen de breekpunten die de data in vier even grote delen splitsen. Meestal is een boxplot verticaal weergegeven, waardoor de y-as de schaal van de variabele weergeeft.De middelste lijn in de boxplot geeft de mediaan van de data aan. De twee boxen erom heen geven het 1e en het 3e kwartiel aan. Dat betekent dat van de datapunten binnen deze twee boxen liggen. De (verticale) lijnen geven aan tussen welke waarden de hoogste en de laagste van de datapunten ligt. Bovendien worden in een boxplot mogelijke outliers visueel weergegeven door middel van zwarte bolletjes of sterretjes. Als er geen outliers weergegeven worden, betekent dit dat je het einde van de verticale lijn kunt interpreteren als het minimum en maximum van de data.
- Beschrijven wat staafdiagrammen zijn.
Bij categorische variabelen hoeven meetwaarden niet samengevoegd te worden om het aantal datapunten per categorie grafisch weer te geven en kan er ook geen histogram gemaakt worden. Er is namelijk geen continue variabele om op de x-as te plaatsen. Wel kunnen op de plek van de x-as de categorieën naast elkaar worden weergegeven en kan op de y-as het aantal datapunten worden gezet. De resulterende grafiek heet een staafdiagram. Hoewel een staafdiagram erg veel lijkt op een histogram, moeten de implicaties van het ontbreken van een x-as niet worden onderschat. Zo kan er voor een staafdiagram, dus voor een categorische variabele, geen density plot gegenereerd worden. Er kan dus ook niet worden gesproken over verdelingsvormen bij categorische variabelen. - Uitleggen wat steekproevenverdelingen zijn.
De steekproevenverdeling, oftewel de sampling distribution, is de theoretische verdeling van een bepaalde maat (bijvoorbeeld het gemiddelde) die je krijgt als je een oneindig aantal steekproeven uit een populatie zou trekken. De theoretische verdelingen van gemiddelden, standaarddeviaties, en spitsheidmaten heten steekproevenverdelingen. Een steekproevenverdeling van gemiddelden bevat dus alle mogelijke gemiddelden die met een steekproef van een gegeven omvang gevonden kunnen worden; en een steekproevenverdeling van standaarddeviaties bevat alle mogelijke standaarddeviaties die met een steekproef van een gegeven omvang gevonden kunnen worden. - Beschrijven dat elke beschrijvingsmaat afkomstig is uit een steekproevenverdeling.
Omdat die steekproevenverdelingen alle mogelijke uitkomsten bevat, kunnen we de redenering ook omdraaien: als we een willekeurige steekproef nemen, komt ons steekproefgemiddelde uit zo’n theoretische steekproevenverdeling met alle mogelijke gemiddelden die we kunnen vinden. En de standaarddeviatie in onze steekproef komt uit een steekproevenverdeling van alle mogelijke standaarddeviaties. - Uitleggen wat de centrale limietstelling is en uitleggen waarom de steekproevenverdeling voor het gemiddelde bijna altijd normaal verdeeld is.
De centrale limietstelling stelt dat naarmate we meer steekproeven trekken, de steekproevenverdeling van het gemiddelde steeds meer op de normaalverdeling zal lijken. Dit is ongeacht de vorm van de populatieverdeling, hoewel er grotere steekproeven nodig zijn om een normale steekproevenverdeling te krijgen naarmate de populatieverdeling zelf meer afwijkt van normaliteit. - Beschrijven wat de standaardfout is.
De standaarddeviatie van een steekproevenverdeling wordt de standaardfout (‘standard error’) genoemd.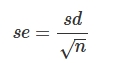
- Beschrijven wat betrouwbaarheidsintervallen zijn.
Het betrouwbaarheidsinterval is een interval om het steekproefgemiddelde heen dat in van de steekproeven het populatiegemiddelde bevat. Dit interval komt overeen met een afwijking van ongeveer twee standaardfouten van het gemiddelde. Dit interval geeft een goede schatting van wat waarschijnlijk het gemiddeld is in de populatie. - Beschrijven wat puntschattingen zijn.
In de praktijk wordt meestal een betrouwbaarheidsinterval van gehanteerd, maar het betrouwbaarheidsinterval kan voor elk willekeurig percentage berekend worden. Het meest extreme geval, een -betrouwbaarheidsinterval, loopt van min oneindig naar plus oneindig. Alleen dan weet je zeker dat het populatiegemiddelde binnen het betrouwbaarheidsinterval ligt, maar dit is natuurlijk niet meer informatief. Een betrouwbaarheidsinterval van is een puntschatting en dus geen interval meer.
OUR TOP post
6. T-toetsen en Cohen’s d
Uitleggen welke vorm de steekproevenverdeling van het verschil tussen gemiddelden…
5. Regressie
Uitleggen hoe regressie zich verhoudt tot correlatie.Correlatie meet de mate…
4. Correlatie
Uitleggen wat een scatterplot is.Een scatterplot is een grafische weergave…
3. Univariatie analyse
Uitleggen wat meetniveaus zijn.Datapunten en datareeksen worden onderverdeeld in verschillende…

-
- May 6, 2026
3. Univariatie analyse
©2024. All rights reserved by Rainbow Theme.